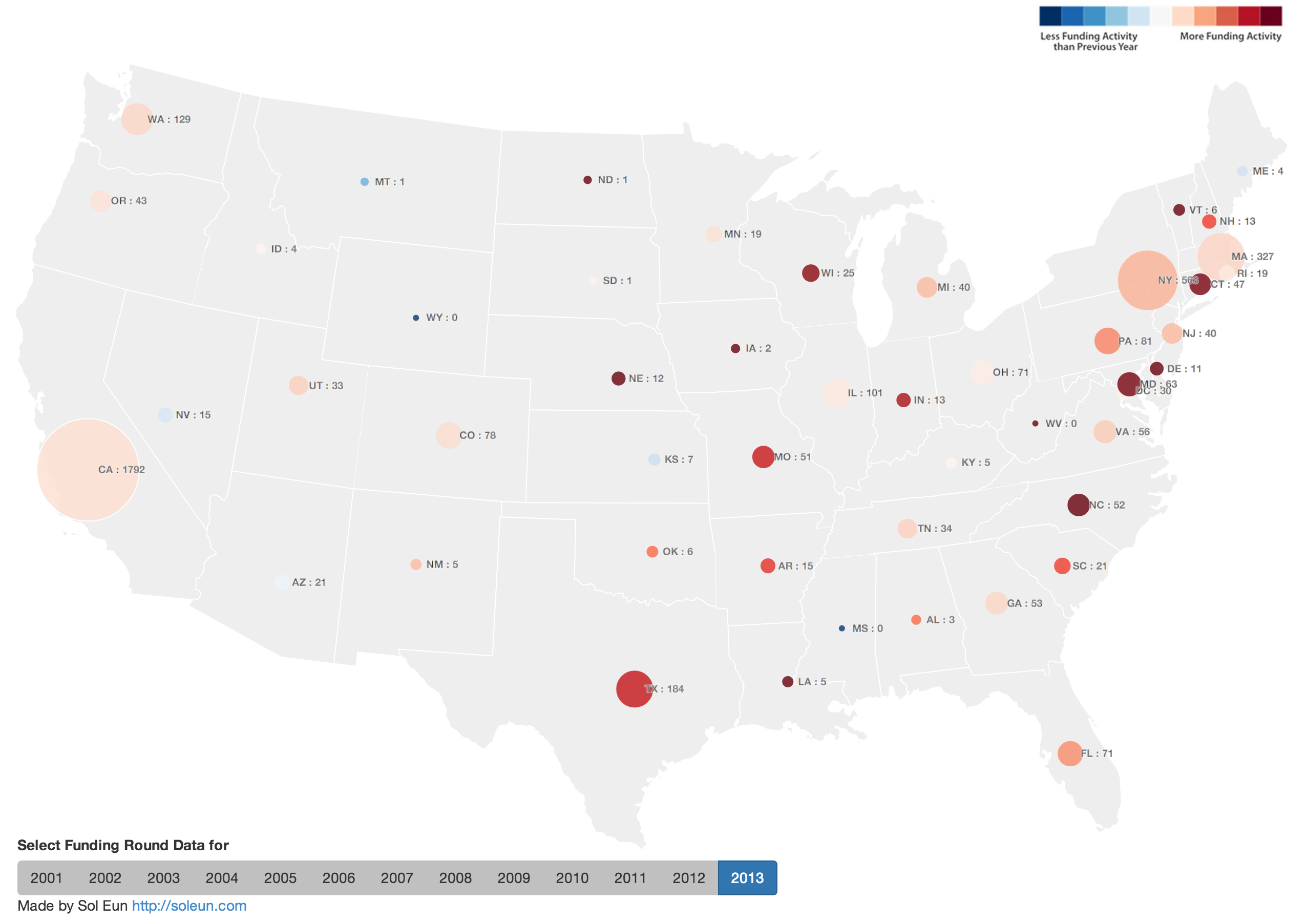
In order to understand the investment activity for private companies in US, I created an interactive map to visualize the number of investment activities(size) and whether the number of activities increased or decreased(color) using CrunchBase data. The number next to state code shows the funding round count for given year. All calculations are based on funding round count not the amount.
Here are some quick observations. If it is too hard to follow, please click “Large View” link above to open the map in a separate tap/window.
- The data shows that there was a big jump of funding activities in 2005 compared to 2004 across US. In 2005, companies in California raised 416 rounds compared to 73 in 2004. That’s 469% increase in just one year. During same period, the number of investment rounds for companies in Massachusetts jumped from 18 to 93, a 416% increase. However, NVCA’s yearbook (Link) does not suggest that such jump existed so it may simply because TechCrunch started in 2005 (Link) so they do not have as much coverage before 2005.
- In 2008, New York passes Massachusetts in terms of number of investment activities and it stays until 2013.
- You will see the beginning of recession in 2008 but both California and New York raised more rounds than they did in 2007. In 2009, the recession continues and it is the only year in which California’s number decreases since 2002.
- In 2011, both Illinois and Ohio companies doubles number of investment activities. For Illinois, it could be due to a state-wide effort to encourage startups such as the launch of Startup Illinois (link). Although I could not find a similar state-wide initiative, there were online articles mentioning school and community-wide activities (Link).
- 2013 shows many east coast states getting higher traction compared to west coast states with North Carolina, Maryland, and Connecticut closing more than double the number from previous year. Although one year is just too short to confirm the trend, it will be interesting to see whether this behavior continues in 2014.
- Please share your own observations in comment section.
- Thanks to CrunchBase for awesome dataset and I love the new look. You should check it out. (Link)





Recent Comments